Hello, I'm Aman, and I assist the dlthub team with various data-related tasks. In a recent project, the Operations team needed to gather information through Google Forms and integrate it into a Notion database. Initially, they tried using the Zapier connector as a quick and cost-effective solution, but it didn’t work as expected. Since we’re at dlthub, where everyone is empowered to create pipelines, I stepped in to develop one that would automate this process.
The solution involved setting up a workflow to automatically sync data from Google Forms to a Notion database. This was achieved using Google Sheets, Google Apps Script, and a dlt pipeline, ensuring that every new form submission was seamlessly transferred to the Notion database without the need for manual intervention.
Link the Google Form to a Google Sheet to save responses in the sheet. Follow Google's documentation for setup.
Step 2: Google Apps Script for Data Transfer
Create a Google Apps Script to send data from Google Sheets to a Notion database via a webhook. This script triggers every time a form response is saved.
Google Apps Script code:
function sendWebhookOnEdit(e) { var sheet = SpreadsheetApp.getActiveSpreadsheet().getActiveSheet(); var range = sheet.getActiveRange(); var updatedRow = range.getRow(); var lastColumn = sheet.getLastColumn(); var headers = sheet.getRange(1, 1, 1, lastColumn).getValues()[0]; var updatedFields = {}; var rowValues = sheet.getRange(updatedRow, 1, 1, lastColumn).getValues()[0]; for (var i = 0; i < headers.length; i++) { updatedFields[headers[i]] = rowValues[i]; } var jsonPayload = JSON.stringify(updatedFields); Logger.log('JSON Payload: ' + jsonPayload); var url = 'https://your-webhook.cloudfunctions.net/to_notion_from_google_forms'; // Replace with your Cloud Function URL var options = { 'method': 'post', 'contentType': 'application/json', 'payload': jsonPayload }; try { var response = UrlFetchApp.fetch(url, options); Logger.log('Response: ' + response.getContentText()); } catch (error) { Logger.log('Failed to send webhook: ' + error.toString()); } }
Step 3: Deploying the ETL Pipeline
Deploy a dlt pipeline to Google Cloud Functions to handle data transfer from Google Sheets to the Notion database. The pipeline is triggered by the Google Apps Script.
Create a Google Cloud function.
Create main.py with the Python code below.
Ensure requirements.txt includes dlt.
Deploy the pipeline to Google Cloud Functions.
Use the function URL in the Google Apps Script.
note
This pipeline uses @dlt.destination decorator which is used to set up custom destinations. Using custom destinations is a part of dlt's reverse ETL capabilities. To read more about dlt's reverse ETL pipelines, please read the documentation here.
Python code for main.py (Google cloud functions) :
import dlt from dlt.common import json from dlt.common.typing import TDataItems from dlt.common.schema import TTableSchema from datetime import datetime from dlt.sources.helpers import requests @dlt.destination(name="notion", batch_size=1, naming_convention="direct", skip_dlt_columns_and_tables=True) definsert_into_notion(items: TDataItems, table: TTableSchema)->None: api_key = dlt.secrets.value # Add your notion API key to "secrets.toml" database_id ="your_notion_database_id"# Replace with your Notion Database ID url ="https://api.notion.com/v1/pages" headers ={ "Authorization":f"Bearer {api_key}", "Content-Type":"application/json", "Notion-Version":"2022-02-22" } for item in items: ifisinstance(item.get('Timestamp'), datetime): item['Timestamp']= item['Timestamp'].isoformat() data ={ "parent":{"database_id": database_id}, "properties":{ "Timestamp":{ "title":[{ "text":{"content": item.get('Timestamp')} }] }, # Add other properties here } } response = requests.post(url, headers=headers, data=json.dumps(data)) print(response.status_code, response.text) defyour_webhook(request): data = request.get_json() Event =[data] pipeline = dlt.pipeline( pipeline_name='platform_to_notion', destination=insert_into_notion, dataset_name='webhooks', full_refresh=True ) pipeline.run(Event, table_name='webhook') return'Event received and processed successfully.'
With everything set up, the workflow automates data transfer as follows:
Form submission saves data in Google Sheets.
Google Apps Script sends a POST request to the Cloud Function.
The dlt pipeline processes the data and updates the Notion database.
Conclusion
We initially considered using Zapier for this small task, but ultimately, handling it ourselves proved to be quite effective. Since we already use an orchestrator for our other automations, the only expense was the time I spent writing and testing the code. This experience demonstrates that dlt is a straightforward and flexible tool, suitable for a variety of scenarios. Essentially, wherever Python can be used, dlt can be applied effectively for data loading, provided it meets your specific needs.
Slowly changing dimensions are a dimensional modelling technique created for historising changes in data.
This technique only works if the dimensions change slower than we read the data, since we would not be able to track changes happening between reads.
For example, if someone changes their address once in a blue moon, we will capture the changes with daily loads - but if
they change their address 3x in a day, we will only see the last state and only capture 2 of the 4 versions of the address.
However, they enable you to track things you could not before such as
Hard deletes
Most of the changes and when they occurred
Different versions of entities valid at different historical times
What is Slowly Changing Dimension Type 2 (SCD2)? and why use it?
The Type 2 subtype of Slowly Changing Dimensions (SCD) manages changes in data over time.
When data changes, a new record is added to the database, but the old record remains unchanged.
Each record includes a timestamp or version number. This allows you to view both the historical
data and the most current data separately.
Traditional data loading methods often involve updating existing records with new information, which results in the loss of historical data.
SCD2 not only preserves an audit trail of data changes but also allows for accurate historical analysis and reporting.
In environments where maintaining a complete historical record of data changes is crucial,
such as in financial services or healthcare, SCD Type 2 plays a vital role. For instance, if a
customer's address changes, SCD2 ensures that the old address is preserved in historical
records while the new address is available for current transactions. This ability to view the
evolution of data over time supports auditing, tracking changes, and analyzing trends without losing
the context of past information. It allows organizations to track the lifecycle of a data
entity across different states.
Here's an example with the customer address change.
Before:
_dlt_valid_from
_dlt_valid_to
customer_key
c1
c2
2024-04-09 18:27:53.734235
NULL
1
123 Elm St
TN
After update:
_dlt_valid_from
_dlt_valid_to
customer_key
c1
c2
2024-04-09 18:27:53.734235
2024-05-01 17:00:00.000000
1
123 Elm St
TN
2024-05-02 08:00:00.000000
NULL
1
456 Oak Ave
TN
In the updated state, the previous address record is closed with an _dlt_valid_to timestamp, and a new record is created
with the new address "456 Oak Ave" effective from May 2, 2024. The NULL in the _dlt_valid_to field for this
new record signifies that it is the current and active address.
This approach ensures that historical data is preserved for audit and compliance purposes, even though the
record is no longer active in the current dataset. It allows businesses to maintain integrity and a full
historical trail of their data changes.
State Before Deletion: Customer Record Active
_dlt_valid_from
_dlt_valid_to
customer_key
c1
c2
2024-04-09 18:27:53.734235
NULL
1
123 Elm St
TN
This table shows the customer record when it was active, with an address at "123 Elm St". The _dlt_valid_to field is NULL, indicating that the record is currently active.
State after deletion: Customer record marked as deleted
_dlt_valid_from
_dlt_valid_to
customer_key
c1
c2
2024-04-09 18:27:53.734235
2024-06-01 10:00:00.000000
1
123 Elm St
TN
In this updated table, the record that was previously active is marked as deleted by updating the _dlt_valid_to field
to reflect the timestamp when the deletion was recognized, in this case, June 1, 2024, at 10:00 AM. The presence
of a non-NULL _dlt_valid_to date indicates that this record is no longer active as of that timestamp.
Learn how to customise your column names and validity dates in our SDC2 docs.
Every record in the SCD2 table needs its own id. We call this a surrogate key. We use it to identify the specific
record or version of an entity, and we can use it when joining to our fact tables for performance (as opposed to joining on entity id + validity time).
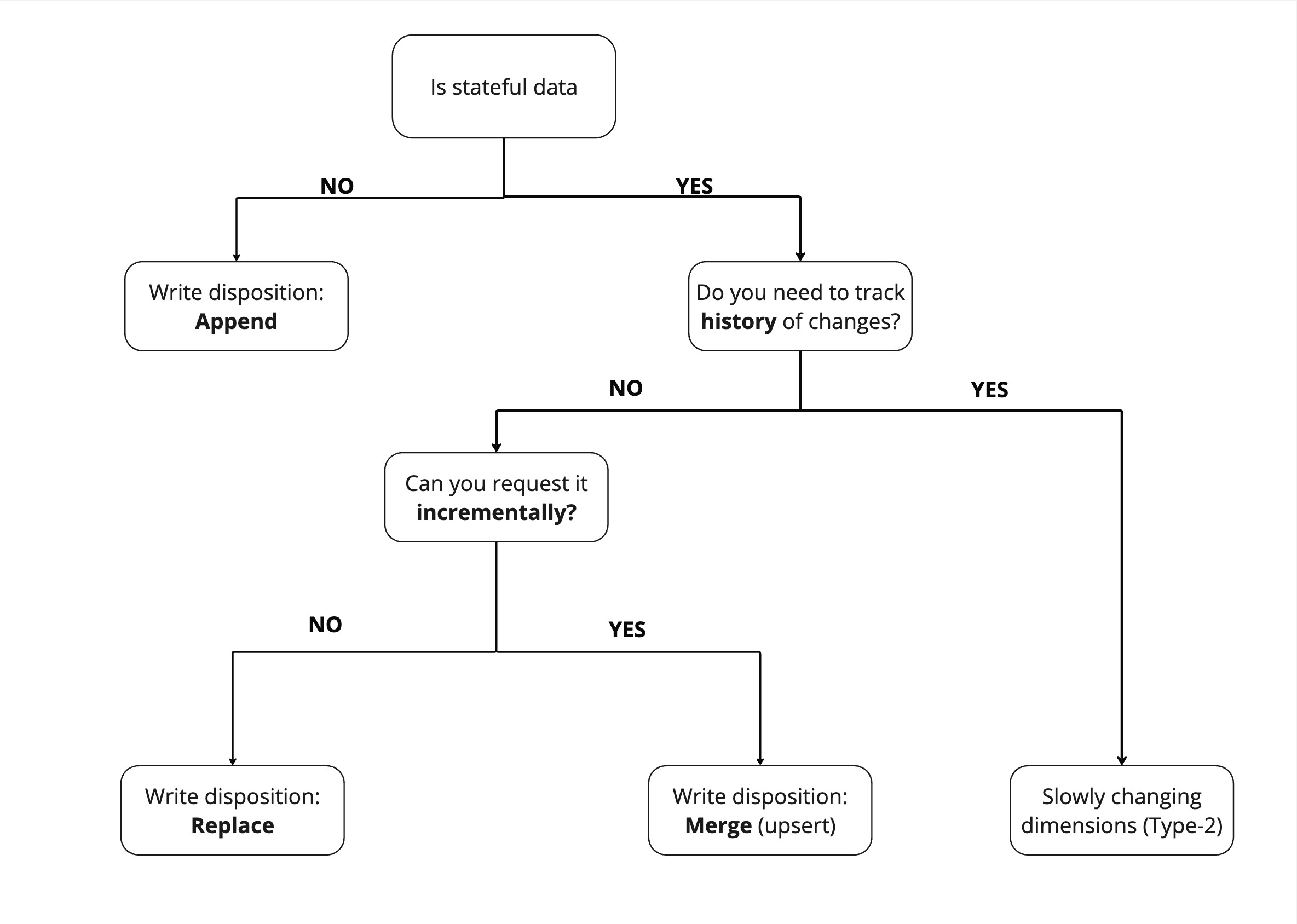
Simple steps to determine data loading strategy and write disposition
This decision flowchart helps determine the most suitable data loading strategy and write disposition:
Is your data stateful? Stateful data is subject to change, like your age. Stateless data does not change, for example, events that happened in the past are stateless.
If your data is stateless, such as logs, you can just increment by appending new logs.
If it is stateful, do you need to track changes to it?
If yes, then use SCD2 to track changes.
If no,
Can you extract it incrementally (new changes only)?
If yes, load incrementally via merge.
If no, re-load fully via replace.
Below is a visual representation of steps discussed above:
Use SCD2 where it makes sense but keep in mind the shortcomings related to the read vs update frequency.
Use dlt to do it at loading and keep everything downstream clean and simple.
But if you want to load pandas dfs to production databases, with all the best practices built-in, check out this documentation or this colab notebook that shows easy handling of complex api data.
I. The background story: Normal people load data too
Hey, I’m Adrian, cofounder of dlt. I’ve been working in the data industry since 2012, doing all kinds of end-to-end things.
In 2017, a hiring team called me a data engineer. As I saw that title brought me a lot of work offers, I kept it and went with it.
But was I doing data engineering? Yes and no. Since my studies were not technical, I always felt some impostor syndrome calling myself a data engineer. I had started as an analyst, did more and more and became an end to end data professional that does everything from building the tech stack, collecting requirements, getting managers to agree on the metrics used 🙄, creating roadmap and hiring a team.
Back in 2022 there was an online conference called Normconf and I ‘felt seen’. As I watched Normconf participants, I could relate more to them than to the data engineer label. No, I am not just writing code and pushing best practices - I am actually just trying to get things done without getting bogged down in bad practice gotchas. And it seemed at this conference that many people felt this way.
Normies: Problem solvers with antipathy for black boxes, gratuitous complexity and external dependencies
At Normconf, "normie" participants often embodied the three fundamental psychological needs identified in Self-Determination Theory: autonomy, competence, and relatedness.
They talked about how they autonomously solved all kinds of problems, related on the pains and gains of their roles, and showed off their competence across the board, in solving problems.
What they did, was what I also did as a data engineer: We start from a business problem, and work back through what needs to be done to understand and solve it.
By very definition, Normie is someone not very specialised at one thing or another, and in our field, even data engineers are jacks of all trades.
What undermines the Normie mission are things that clash with the basic needs, from uncustomisable products, to vendors that add bottlenecks and unreliable dependencies.
Encountering friction between data engineers and Python-first analysts
Before becoming a co-founder of dlt I had 5 interesting years as a startup employee, a half-year nightmare in a corporation with no autonomy or mastery (I got fired for refusing the madness, and it was such a huge relief), followed by 5 fun, rewarding and adventure-filled years of freelancing. Much of my work was “build&hire” which usually meant building a first time data warehouse and hiring a team for it. The setups that I did were bespoke to the businesses that were getting them, including the teams - Meaning, the technical complexity was also tailored to the (lack of) technical culture of the companies I was building for.
In this time, I saw an acute friction between data engineers and Python-first analysts, mostly around the fact that data engineers easily become a bottleneck and data scientists are forced to pick up the slack. And of course, this causes other issues that might further complicate the life of the data engineer, while still not being a good solution for the data consumers.
So at this point I started building boilerplate code for data warehouses and learning how to better cater to the entire team.
II. The initial idea: pandas.df.to_sql() with data engineering best practices
After a few attempts I ended up with the hypothesis that df.to_sql() is the natural abstraction a data person would use - I have a table here, I want a table there, shouldn’t be harder than a function call right?
Right.
Except that particular function call is anything but data engineering complete. A single run will do what it promises. A production pipeline will also have many additional requirements. In the early days, we wrote up an ideal list of features that should be auto-handled (spoiler alert: today dlt does all that and more). Read on for the wish list:
Our dream: a tool that meets production pipelines requirements
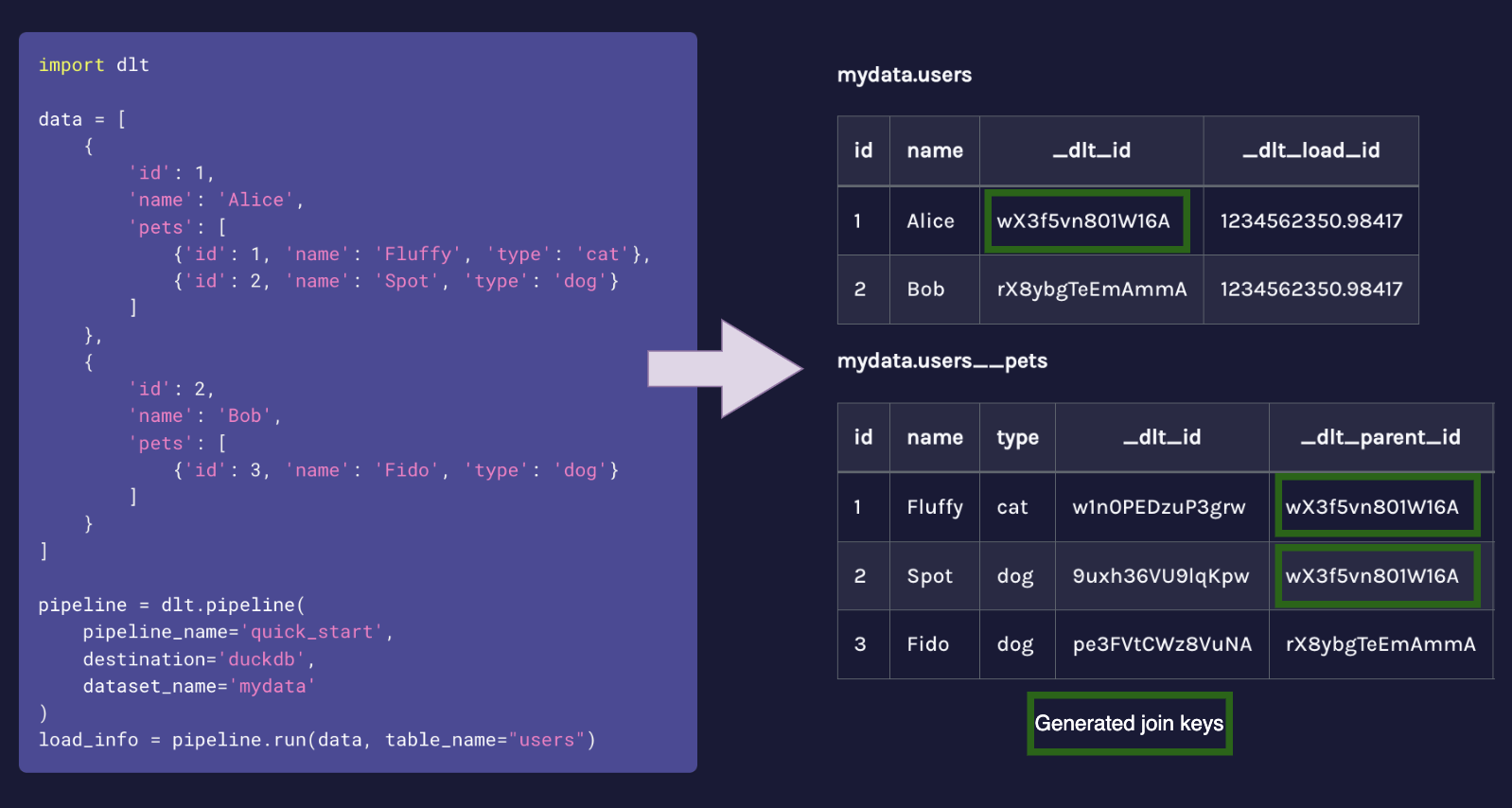
Wouldn’t it be nice if we could auto-flatten and unpack nested structures into tables with generated join keys?
Wouldn’t it be nice if data types were properly defined and managed?
Wouldn’t it be nice if we could load the data incrementally, meaning retain some state to know where to start from?
Wouldn’t it be nice if this incremental load was bound to a way to do incremental extraction?
Wouldn’t it be nice if we didn’t run out of memory?
Wouldn’t it be nice if we got alerted/notified when schemas change?
Wouldn’t it be nice if schema changes were self healing?
Wouldn’t it be nice if I could run it all in parallel, or do async calls?
Wouldn’t it be nice if it ran on different databases too, from dev to prod?
Wouldn’t it be nice if it offered requests with built in retries for those nasty unreliable apis (Hey Zendesk, why you fail on call 99998/100000?)
Wouldn’t it be nice if we had some extraction helpers like pagination detection?
How did we go about it? At first dlt was created as an engine to iron out its functionality. During this time, it was deployed it in several projects, from startups to enterprises, particularly to accelerate data pipeline building in a robust way.
A while later, to prepare this engine for the general public, we created the current interface on top of it. We then tested it in a workshop with many “Normies” of which over 50% were pre-employment learners.
For the workshop we broke down the steps to build an incremental pipeline into 20 steps. In the 6 hour workshop we asked people to react on Slack to each “checkpoint”. We then exported the slack data and loaded it with dlt, exposing the completion rate per checkpoint. Turns out, it was 100%.
Everyone who started, managed to build the pipeline. “This is it!” we thought, and spend the next 6 months preparing our docs and adding some plugins for easy deployment.
We finally launched dlt mid 2023 to the general public. Our initial community was mostly data engineers who had been using dlt without docs,
managing from reading code. As we hoped a lot of “normies” are using dlt, too!
A product is a sum of many parts. For us dlt is not only the dlt library and interface, but also our docs and Slack community and the support and discussions there.
In the early days of dlt we talked to Sebastian Ramirez from FastAPI who told us that he spends 2/3 of his FastAPI time writing documentation.
In this vein, from the beginning docs were very important to us and we quickly adopted our own docs standard.
However, when we originally launched dlt, we found that different user types, especially Normies, expect different things from our docs, and because we asked for feedback, they told us.
So overall, we were not satisfied to stop there.
"Can you make your docs more like my favorite tool's docs?"
To this end we built and embedded our own docs helper in our docs.
The result? The docs helper has been running for a year and we currently see around 300 questions per day. Comparing this to other communities that do AI support on Slack, that’s almost 2 orders of magnitude difference in question volume by community size.
We think this is a good thing, and a result of several factors.
Embedded in docs means at the right place at the right time. Available to anyone, whether they use Slack or not.
Conversations are private and anonymous. This reduces the emotional barrier of asking. We suspect this is great for the many “Normies” / “problem solvers” that work in data.
The questions are different than in our Slack community: Many questions are around “Setup and configuration”, “Troubleshooting” and “General questions” about dlt architecture. In Slack, we see the questions that our docs or assistant could not answer.
The bot is conversational and will remember recent context, enabling it to be particularly helpful. This is different from the “question answering service” that many Slack bots offer, which do not keep context once a question was answered. By retaining context, it’s possible to reach a useful outcome even if it doesn’t come in the first reply.
dlt = “pip install and go” - the fastest way to create a pipeline and source
dlt offers a small number of verified sources, but encourages you to build your own. As we
mentioned, creating an ad hoc dlt pipeline and source is
dramatically simpler compared to other python libraries.
Maintaining a custom dlt source in production takes no time at all because the pipeline won't break unless the source stops existing.
The sources you build and run that are not shared back into the verified sources are what we call “private sources”.
By the end of 2023, our community had already built 1,000 private sources, 2,000 by early March. We
are now at the end of q2 2024 and we see 5,000 private sources.
We recently launched additional tooling that helps our users build sources. If you wish to try our python-first
dict-based declarative approach to building sources, check out the relevant post.
Rest api connector
Openapi based pipeline generator that configures the rest api connector.
Alena introduces the generator and troubleshoots the outcome in 4min:
Both tools are LLM-free pipeline generators. I stress LLM free, because in our experience, GPT can
do some things to some extent - so if we ask it to complete 10 tasks to produce a pipeline, each
having 50-90% accuracy, we can expect very low success rates.
To get around this problem, we built from the OpenAPI standard which contains information that can
be turned into a pipeline algorithmically. OpenAPI is an Api spec that’s also used by FastAPI and
constantly growing in popularity, with around 50% of apis currently supporting it.
By leveraging the data in the spec, we are able to have a basic pipeline. Our generator also infers
some other pieces of information algorithmically to make the pipeline incremental and add some other useful details.
Of course, generation doesn’t always work but you can take the generated pipeline and make the final
adjustments to have a standard REST API config-based pipeline that won’t suffer from code smells.
The real benefit of this declarative source is not at building time - A declarative interface requires
more upfront knowledge. Instead, by having this option, we enable minimalistic pipelines that anyone could
maintain, including non coders or human-assisted LLMs. After all, LLMs are particularly proficient at translating configurations back and forth.
Want to influence us? we listen, so you’re welcome to discuss with us in our slack channel #4-discussions
dlt is an open core product, meaning it won’t be gated to push you to the paid version at some point.
Instead, much like Kafka and Confluent, we will offer things around dlt to help you leverage it in your context.
If you are interested to help us research what’s needed, you can apply for our design partnership
program, that aims to help you deploy dlt, while helping us learn about your challenges.
If you like the idea of dlt, there is one thing that would help us:
Set aside 30min and try it.
See resource below.
We often hear variations of “oh i postponed dlt so long but it only took a few minutes to get going, wish I hadn’t
installed [other tool] which took 2 weeks to set up properly and now we need to maintain or replace”, so don't be that guy.
Here are some notebooks and docs to open your appetite:
OpenAPI is the world's most widely used API description standard. You may have heard about swagger docs? those are docs generated from the spec.
In 2021 an information-security company named Assetnote scanned the web and unearthed 200,000 public
OpenAPI files.
Modern API frameworks like FastAPI generate such specifications automatically.
A pipeline is a series of datapoints or decisions about how to extract and load the data, expressed as code or config. I say decisions because building a pipeline can be boiled down to inspecting a documentation or response and deciding how to write the code.
Our tool does its best to pick out the necessary details and detect the rest to generate the complete pipeline for you.
The information required for taking those decisions comes from:
This is something we are also learning about. We did an internal hackathon where we each built a few pipelines with this generator. In our experiments with APIs for which we had credentials, it worked pretty well.
However, we cannot undertake a big detour from our work to manually test each possible pipeline, so your feedback will be invaluable.
So please, if you try it, let us know how well it worked - and ideally, add the spec you used to our repository.
Once a pipeline is created, it is a fully configurable instance of the REST API Source.
So if anything did not go smoothly, you can make the final tweaks.
You can learn how to adjust the generated pipeline by reading our REST API Source documentation.
No. This is a potential future enhancement, so maybe later.
The pipelines are generated algorithmically with deterministic outcomes. This way, we have more control over the quality of the decisions.
If we took an LLM-first approach, the errors would compound and put the burden back on the data person.
We are however considering using LLM-assists for the things that the algorithmic approach can't detect. Another avenue could be generating the OpenAPI spec from website docs.
So we are eager to get feedback from you on what works and what needs work, enabling us to improve it.
Solving data engineering headaches in the open source is a team sport.
We got this far with your feedback and help (especially on REST API source), and are counting on your continuous usage and engagement
to steer our pushing of what's possible into uncharted, but needed directions.
Got an OpenAPI spec? Add it to our specs repository so others may use it. If the spec doesn't work, please note that in the PR and we will use it for R&D.
Thank you for being part of our community and for building the future of ETL together!
Hello, I'm Aman Gupta. Over the past eight years, I have navigated the structured world of civil engineering, but recently, I have found myself captivated by data engineering. Initially, I knew how to stack bricks and build structural pipelines. But this newfound interest has helped me build data pipelines, and most of all, it was sparked by a workshop hosted by dlt.
info
dlt (data loading tool) is an open-source library that you can add to your Python scripts to load data from various and often messy data sources into well-structured, live datasets.
The dlt workshop took place in November 2022, co-hosted by Adrian Brudaru, my former mentor and co-founder of dlt.
An opportunity arose when another client needed data migration from FreshDesk to BigQuery. I crafted a basic pipeline version, initially designed to support my use case. Upon presenting my basic pipeline to the dlt team, Alena Astrakhatseva, a team member, generously offered to review it and refine it into a community-verified source.
My first iteration was straightforward—loading data in replace mode. While adequate for initial purposes, a verified source demanded features like pagination and incremental loading. To achieve this, I developed an API client tailored for the Freshdesk API, integrating rate limit handling and pagination:
classFreshdeskClient: """ Client for making authenticated requests to the Freshdesk API. It incorporates API requests with rate limit and pagination. """ def__init__(self, api_key:str, domain:str): # Contains stuff like domain, credentials and base URL. pass def_request_with_rate_limit(self, url:str,**kwargs: Any)-> requests.Response: # Handles rate limits in HTTP requests and ensures that the client doesn't exceed the limit set by the server. pass defpaginated_response( self, endpoint:str, per_page:int, updated_at: Optional[str]=None, )-> Iterable[TDataItem]: # Fetches a paginated response from a specified endpoint. pass
To further make the pipeline effective, I developed dlt resources that could handle incremental data loading. This involved creating resources that used dlt's incremental functionality to fetch only new or updated data:
defincremental_resource( endpoint:str, updated_at: Optional[Any]= dlt.sources.incremental( "updated_at", initial_value="2022-01-01T00:00:00Z" ), )-> Generator[Dict[Any, Any], Any,None]: """ Fetches and yields paginated data from a specified API endpoint. Each page of data is fetched based on the `updated_at` timestamp to ensure incremental loading. """ # Retrieve the last updated timestamp to fetch only new or updated records. updated_at = updated_at.last_value # Use the FreshdeskClient instance to fetch paginated responses yieldfrom freshdesk.paginated_response( endpoint=endpoint, per_page=per_page, updated_at=updated_at, )
With the steps defined above, I was able to load the data from Freshdesk to BigQuery and use the pipeline in production. Here’s a summary of the steps I followed:
Created a Freshdesk API token with sufficient privileges.
Created an API client to make requests to the Freshdesk API with rate limit and pagination.
Made incremental requests to this client based on the “updated_at” field in the response.
Ran the pipeline using the Python script.
While my journey from civil engineering to data engineering was initially intimidating, it has proved to be a profound learning experience. Writing a pipeline with dlt mirrors the simplicity of a GET request: you request data, yield it, and it flows from the source to its destination. Now, I help other clients integrate dlt to streamline their data workflows, which has been an invaluable part of my professional growth.
In conclusion, diving into data engineering has expanded my technical skill set and provided a new lens through which I view challenges and solutions. As for me, the lens view mainly was concrete and steel a couple of years back, which has now begun to notice the pipelines of the data world.
Data engineering has proved both challenging, satisfying, and a good career option for me till now. For those interested in the detailed workings of these pipelines, I encourage exploring dlt's GitHub repository or diving into the documentation.
Our new REST API Source is a short, declarative configuration driven way of creating sources.
Our new REST API Client is a collection of Python helpers used by the above source, which you can also use as a standalone, config-free, imperative high-level abstraction for building pipelines.
Why REST configuration pipeline? Obviously, we need one!
But of course! Why repeat write all this code for requests and loading, when we could write it once and re-use it with different APIs with different configs?
Once you have built a few pipelines from REST APIs, you can recognise we could, instead of writing code, write configuration.
And if you’ve been in a few larger more mature companies, you will have seen a variety of home-grown solutions that look similar. You might also have seen such solutions as commercial products or offerings.
So far we have seen many REST API configurators and products — they suffer from predictable flaws:
Local homebrewed flavors are local for a reason: They aren’t suitable for the broad audience. And often if you ask the users/beneficiaries of these frameworks, they will sometimes argue that they aren’t suitable for anyone at all.
Commercial products are yet another data product that doesn’t plug into your stack, brings black boxes and removes autonomy, so they simply aren’t an acceptable solution in many cases.
So how can dlt do better?
Because it can keep the best of both worlds: the autonomy of a library, the quality of a commercial product.
As you will see further, we created not just a standalone “configuration-based source builder” but we also expose the REST API client used enabling its use directly in code.
The push for this is coming from you, the community. While we had considered the concept before, there were many things dlt needed before creating a new way to build pipelines. A declarative extractor after all, would not make dlt easier to adopt, because a declarative approach requires more upfront knowledge.
And thank you Francesco Mucio and Willi Müller for re-opening the topic, and creating video tutorials.
And last but not least, thank you to dlt team’s Anton Burnashev (also known for gspread library) for building it out!
The outcome? Two Python-only interfaces, one declarative, one imperative.
dlt’s REST API Source is a Python dictionary-first declarative source builder, that has enhanced flexibility, supports callable passes, native config validations via python dictionaries, and composability directly in your scripts. It enables generating sources dynamically during runtime, enabling straightforward, manual or automated workflows for adapting sources to changes.
dlt’s REST API Client is the low-level abstraction that powers the REST API Source. You can use it in your imperative code for more automation and brevity, if you do not wish to use the higher level declarative interface.
Useful for those who frequently build new pipelines
If you are on a team with 2-3 pipelines that never change much you likely won’t see much benefit from our latest tool.
What we observe from early feedback a declarative extractor is great at is enabling easier work at scale.
We heard excitement about the REST API Source from:
companies with many pipelines that frequently create new pipelines,
data platform teams,
freelancers and agencies,
folks who want to generate pipelines with LLMs and need a simple interface.
Since this is a declarative interface, we can’t make things up as we go along, and instead need to understand what we want to do upfront and declare that.
In some cases, we might not have the information upfront, so we will show you how to get that info during your development workflow.
Depending on how you learn better, you can either watch the videos that our community members made, or follow the walkthrough below.
If you prefer to do things at your own pace, try the workflow walkthrough, which will show you the workflow of using the declarative interface.
In the example below, we will show how to create an API integration with 2 endpoints. One of these is a child resource, using the data from the parent endpoint to make a new request.
Identify if you have any dependent request patterns such as first get ids in a list, then use id for requesting details.
For GitHub, we might do the below or any other dependent requests. Colab example.:
Get all repos of an org https://api.github.com/orgs/{org}/repos.
Then get all contributors https://api.github.com/repos/{owner}/{repo}/contributors.
How does pagination work? Is there any? Do we know the exact pattern? Colab example.
On GitHub, we have consistent pagination between endpoints that looks like this link_header = response.headers.get('Link', None).
Identify the necessary information for incremental loading, Colab example:
Will any endpoints be loaded incrementally?
What columns will you use for incremental extraction and loading?
GitHub example: We can extract new issues by requesting issues after a particular time: https://api.github.com/repos/{repo_owner}/{repo_name}/issues?since={since}.
Configuration Checklist: Checking responses during development
Data path:
You could print the source and see what is yielded. Colab example.
Unless you had full documentation at point 4 (which we did), you likely need to still figure out some details on how pagination works.
To do that, we suggest using curl or a second python script to do a request and inspect the response. This gives you flexibility to try anything. Colab example.
Or you could print the source as above - but if there is metadata in headers etc, you might miss it.
If you are using a narrow screen, scroll the snippet below to look for the numbers designating each component (n).
# This source has 2 resources: # - issues: Parent resource, retrieves issues incl. issue number # - issues_comments: Child resource which needs the issue number from parent. import os from rest_api import RESTAPIConfig github_config: RESTAPIConfig ={ "client":{ "base_url":"https://api.github.com/repos/dlt-hub/dlt/",#(1) # Optional auth for improving rate limits # "auth": { #(2) # "token": os.environ.get('GITHUB_TOKEN'), # }, }, # The paginator is autodetected, but we can pass it explicitly #(3) # "paginator": { # "type": "header_link", # "next_url_path": "paging.link", # } # We can declare generic settings in one place # Our data is stateful so we load it incrementally by merging on id "resource_defaults":{ "primary_key":"id",#(4) "write_disposition":"merge",#(4) # these are request params specific to GitHub "endpoint":{ "params":{ "per_page":10, }, }, }, "resources":[ # This is the first resource - issues { "name":"issues", "endpoint":{ "path":"issues",#(1) "params":{ "sort":"updated", "direction":"desc", "state":"open", "since":{ "type":"incremental",#(4) "cursor_path":"updated_at",#(4) "initial_value":"2024-01-25T11:21:28Z",#(4) }, } }, }, # Configuration for fetching comments on issues #(5) # This is a child resource - as in, it needs something from another { "name":"issue_comments", "endpoint":{ "path":"issues/{issue_number}/comments",#(1) # For child resources, you can use values from the parent resource for params. "params":{ "issue_number":{ # Use type "resolve" to define child endpoint wich should be resolved "type":"resolve", # Parent endpoint "resource":"issues", # The specific field in the issues resource to use for resolution "field":"number", } }, }, # A list of fields, from the parent resource, which will be included in the child resource output. "include_from_parent":["id"], }, ], }
As we mentioned, there’s also a REST Client - an imperative way to use the same abstractions, for example, the auto-paginator - check out this runnable snippet:
from dlt.sources.helpers.rest_client import RESTClient # Initialize the RESTClient with the Pokémon API base URL client = RESTClient(base_url="https://pokeapi.co/api/v2") # Using the paginate method to automatically handle pagination for page in client.paginate("/pokemon"): print(page)
We are going to generate a bunch of sources from OpenAPI specs — stay tuned for an update in a couple of weeks!
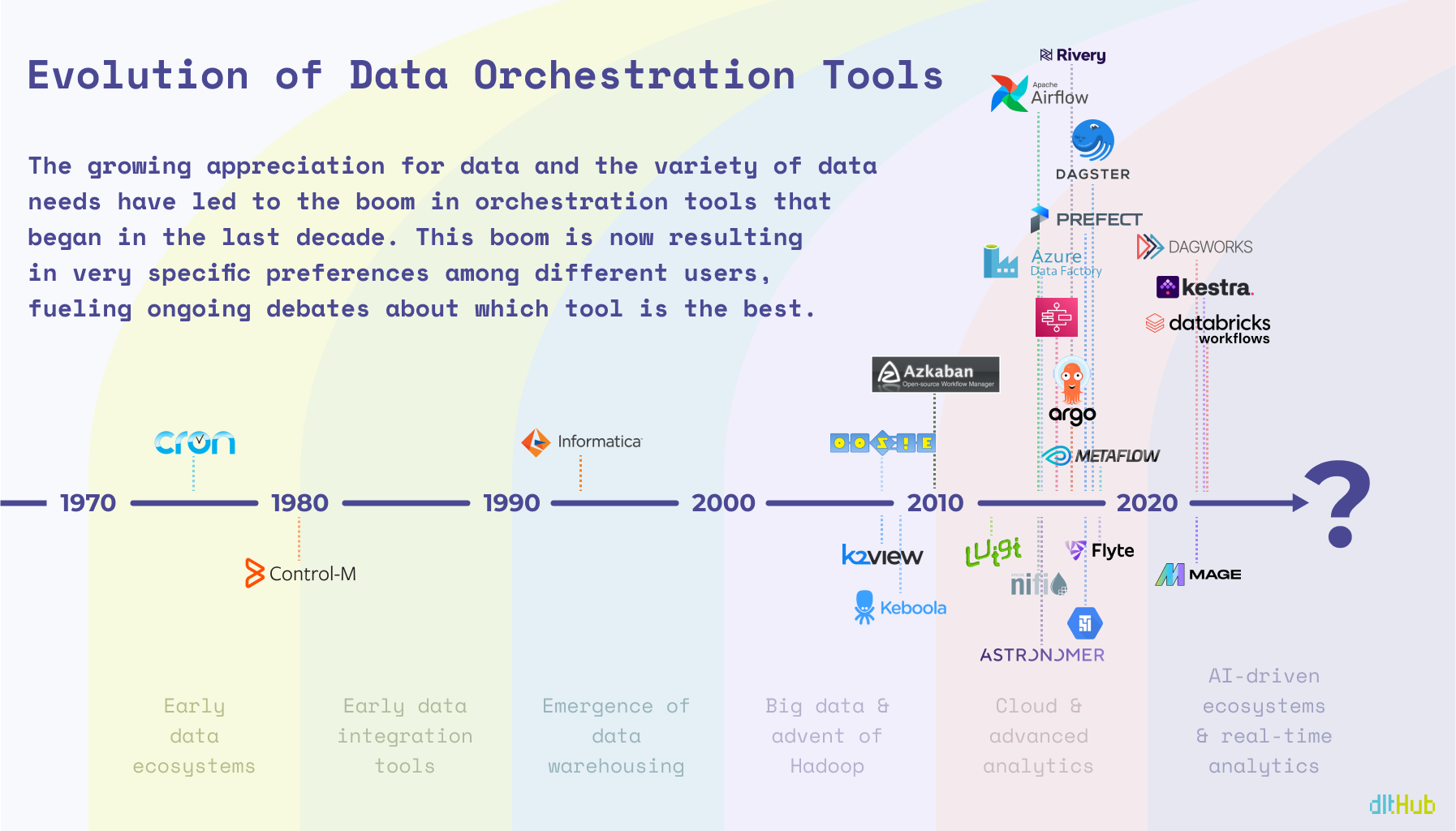
It's been nearly half a century since cron was first introduced, and now we have a handful orchestration tools that go way beyond just scheduling tasks. With data folks constantly debating about which tools are top-notch and which ones should leave the scene, it's like we're at a turning point in the evolution of these tools. By that I mean the term 'orchestrator' has become kind of a catch-all, and that's causing some confusion because we're using this one word to talk about a bunch of different things.
Think about the word “date.” It can mean a fruit, a romantic outing, or a day on the calendar, right? We usually figure out which one it is from the context, but what does context mean when it comes to orchestration? It might sound like a simple question, but it's pretty important to get this straight.
And here's a funny thing: some people, after eating an odd-tasting date (the fruit, of course), are so put off that they naively swear off going on romantic dates altogether. It's an overly exaggerated figurative way of looking at it, but it shows how one bad experience can color our view of something completely different. That's kind of what's happening with orchestration tools. If someone had a bad time with one tool, they might be overly critical towards another, even though it might be a totally different experience.
So the context in terms of orchestration tools seems to be primarily defined by one thing - WHEN a specific tool was first introduced to the market (aside from the obvious factors like the technical background of the person discussing these tools and their tendency to be a chronic complainer 🙄).
Cron was initially released in 1975 and is undoubtedly the father of all scheduling tools, including orchestrators, but I’m assuming Cron didn’t anticipate this many offspring in the field of data (or perhaps it did). As Oracle brought the first commercial relational database to market in 1979, people started to realize that data needs to be moved on schedule, and without manual effort. And it was doable, with the help of Control-M, though it was more of a general workflow automation tool that didn’t pay special attention to data workflows.
Basically, since the solutions weren’t data driven at that time, it was more “The job gets done, but without a guarantee of data quality.”
Unlike Control-M, Informatica was designed for data operations in mind from the beginning. As data started to spread across entire companies, advanced OLAPs started to emerge with a broad use of datawarehousing. Now data not only needed to be moved, but integrated across many systems and users. The data orchestration solution from Informatica was inevitably influenced by the rising popularity of the contemporary drag-and-drop concept, that is, to the detriment of many modern data engineers who would recommend to skip Informatica and other GUI based ETL tools that offer ‘visual programming’.
As the creator of Airflow, Max Beauchemin, said: “There's a multitude of reasons why complex pieces of software are not developed using drag and drop tools: it's that ultimately code is the best abstraction there is for software.”
With traditional ETL tools, such as IBM DataStage and Talend, becoming well-established in the 1990s and early 2000s, the big data movement started gaining its momentum with Hadoop as the main star. Oozie, later made open-source in 2011, was tasked with workflow scheduling of Hadoop jobs, with closed-source solutions, like K2View starting to operate behind the curtains.
Fast forward a bit, and the scene exploded, with Airflow quickly becoming the heavyweight champ, while every big data service out there began rolling out their own orchestrators. This burst brought diversity, but with diversity came a maze of complexity. All of a sudden, there’s an orchestrator for everyone — whether you’re chasing features or just trying to make your budget work 👀 — picking the perfect one for your needs has gotten even trickier.
The thing is that every tool out there has some inconvenient truths, and real question isn't about escaping the headache — it's about choosing your type of headache. Hence, the endless sea of “versus” articles, blog posts, and guides trying to help you pick your personal battle.
What I'm getting at is this: we're all a bit biased by the "law of the instrument." You know, the whole “If all you have is a hammer, everything looks like a nail” thing. Most engineers probably grabbed the latest or most hyped tool when they first dipped their toes into data orchestration and have stuck with it ever since. Sure, Airflow is the belle of the ball for the community, but there's a whole lineup of contenders vying for the spotlight.
And there are obviously those who would relate to the following:
I'm no oracle or tech guru, but it's pretty obvious that at their core, most data orchestration tools are pretty similar. They're like building blocks that can be put together in different ways—some features come, some go, and users are always learning something new or dropping something old. So, what's really going to make a difference down the line is NOT just about having the coolest features. It's more about having a strong community that's all in on making the product better, a welcoming onboarding process that doesn't feel like rocket science, and finding that sweet spot between making things simple to use and letting users tweak things just the way they like.
In other words, it's not just about what the tools can do, but how people feel about using them, learning them, contributing to them, and obviously how much they spend to maintain them. That's likely where the future winners in the data orchestration game will stand out. But don’t get me wrong, features are important — it's just that there are other things equally important.
I’ve been working on this article for a WHILE now, and, honestly, it's been a bit of a headache trying to gather any solid, objective info on which data orchestration tool tops the charts. The more I think about it, the more I realise it's probably because trying to measure "the best" or "most popular" is a bit like trying to catch smoke with your bare hands — pretty subjective by nature. Plus, only testing them with non-production level data probably wasn't my brightest move.
However, I did create a fun little project where I analysed the sentiment of comments on articles about selected data orchestrators on Hacker News and gathered Google Trends data for the past year.
Just a heads-up, though: the results are BY NO MEANS reliable and are skewed due to some fun with words. For instance, searching for “Prefect” kept leading me to articles about Japanese prefectures, “Keboola” resulted in Kool-Aid content, and “Luigi”... well, let’s just say I ran into Mario’s brother more than once 😂.
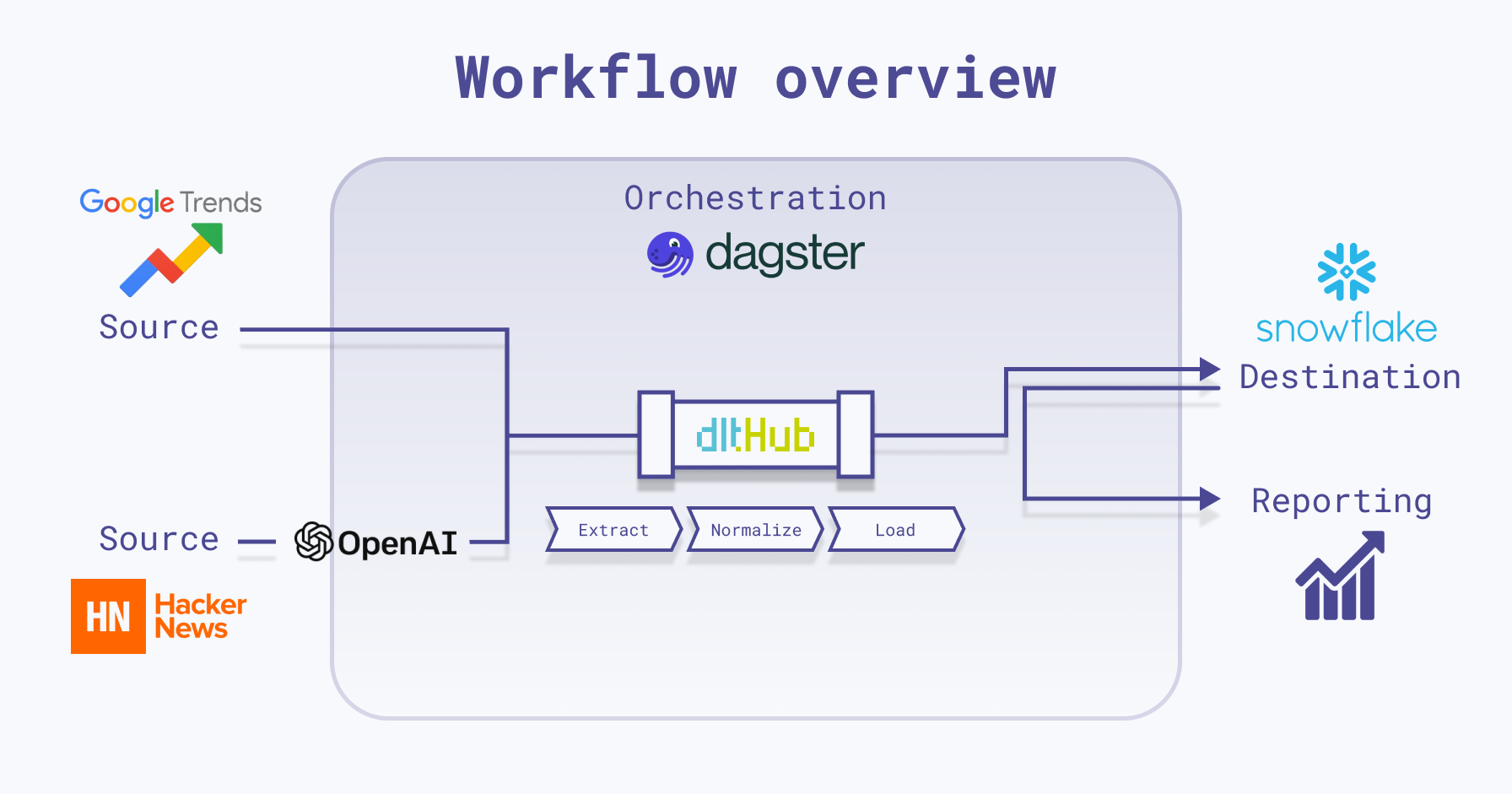
I used Dagster and dlt to load data into Snowflake, and since both of them have integrations with Snowflake, it was easy to set things up and have them all running:
This project is very minimal, including just what's needed to run Dagster locally with dlt. Here's a quick breakdown of the repo’s structure:
.dlt: Utilized by the dlt library for storing configuration and sensitive information. The Dagster project is set up to fetch secret values from this directory as well.
charts: Used to store chart images generated by assets.
dlt_dagster_snowflake_demo: Your Dagster package, comprising Dagster assets, dlt resources, Dagster resources, and general project configurations.
In the resources folder, the following two Dagster resources are defined as classes:
DltPipeline: This is our dlt object defined as a Dagster ConfigurableResource that creates and runs a dlt pipeline with the specified data and table name. It will later be used in our Dagster assets to load data into Snowflake.
classDltPipeline(ConfigurableResource): # Initialize resource with pipeline details pipeline_name:str dataset_name:str destination:str defcreate_pipeline(self, resource_data, table_name): """ Creates and runs a dlt pipeline with specified data and table name. Args: resource_data: The data to be processed by the pipeline. table_name: The name of the table where data will be loaded. Returns: The result of the pipeline execution. """ # Configure the dlt pipeline with your destination details pipeline = dlt.pipeline( pipeline_name=self.pipeline_name, destination=self.destination, dataset_name=self.dataset_name ) # Run the pipeline with your parameters load_info = pipeline.run(resource_data, table_name=table_name) return load_info
LocalFileStorage: Manages the local file storage, ensuring the storage directory exists and allowing data to be written to files within it. It will be later used in our Dagster assets to save images into the charts folder.
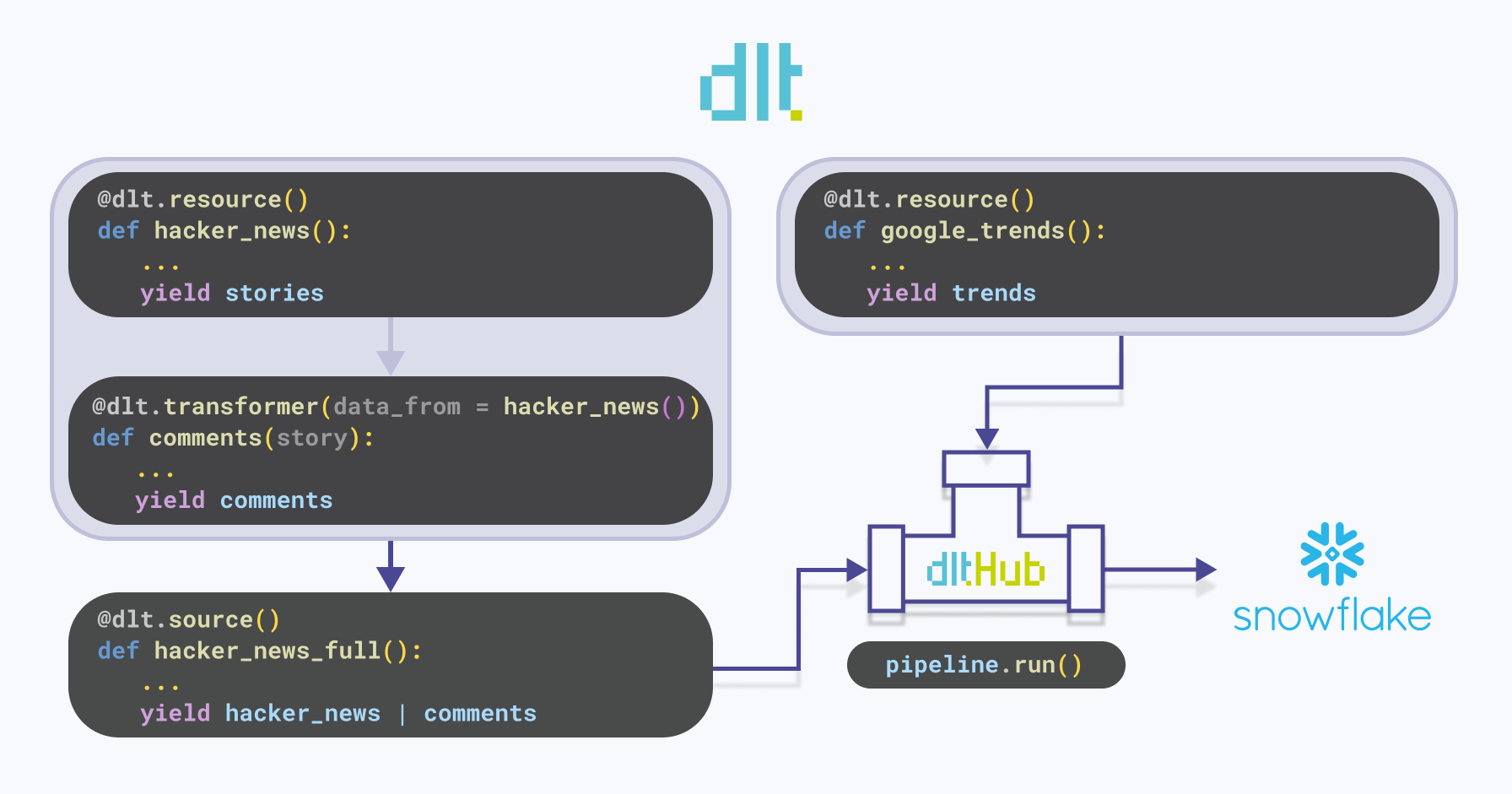
In the dlt folder within dlt_dagster_snowflake_demo, necessary dlt resources and sources are defined. Below is a visual representation illustrating the functionality of dlt:
hacker_news: A dlt resource that yields stories related to specified orchestration tools from Hackernews. For each tool, it retrieves the top 5 stories that have at least one comment. The stories are then appended to the existing data.
Note that the write_disposition can also be set to merge or replace:
The merge write disposition merges the new data from the resource with the existing data at the destination. It requires a primary_key to be specified for the resource. More details can be found here.
The replace write disposition replaces the data in the destination with the data from the resource. It deletes all the classes and objects and recreates the schema before loading the data.
comments: A dlt transformer - a resource that receives data from another resource. It fetches comments for each story yielded by the hacker_news function.
hacker_news_full: A dlt source that extracts data from the source location using one or more resource components, such as hacker_news and comments. To illustrate, if the source is a database, a resource corresponds to a table within that database.
google_trends: A dlt resource that fetches Google Trends data for specified orchestration tools. It attempts to retrieve the data multiple times in case of failures or empty responses. The retrieved data is then appended to the existing data.
As you may have noticed, the dlt library is designed to handle the unnesting of data internally. When you retrieve data from APIs like Hacker News or Google Trends, dlt automatically unpacks the nested structures into relational tables, creating and linking child and parent tables. This is achieved through unique identifiers (_dlt_id and _dlt_parent_id) that link child tables to specific rows in the parent table. However, it's important to note that you have control over how this unnesting is done.
Alright, so once you've got your Dagster assets all materialized and data loaded into Snowflake, let's take a peek at what you might see:
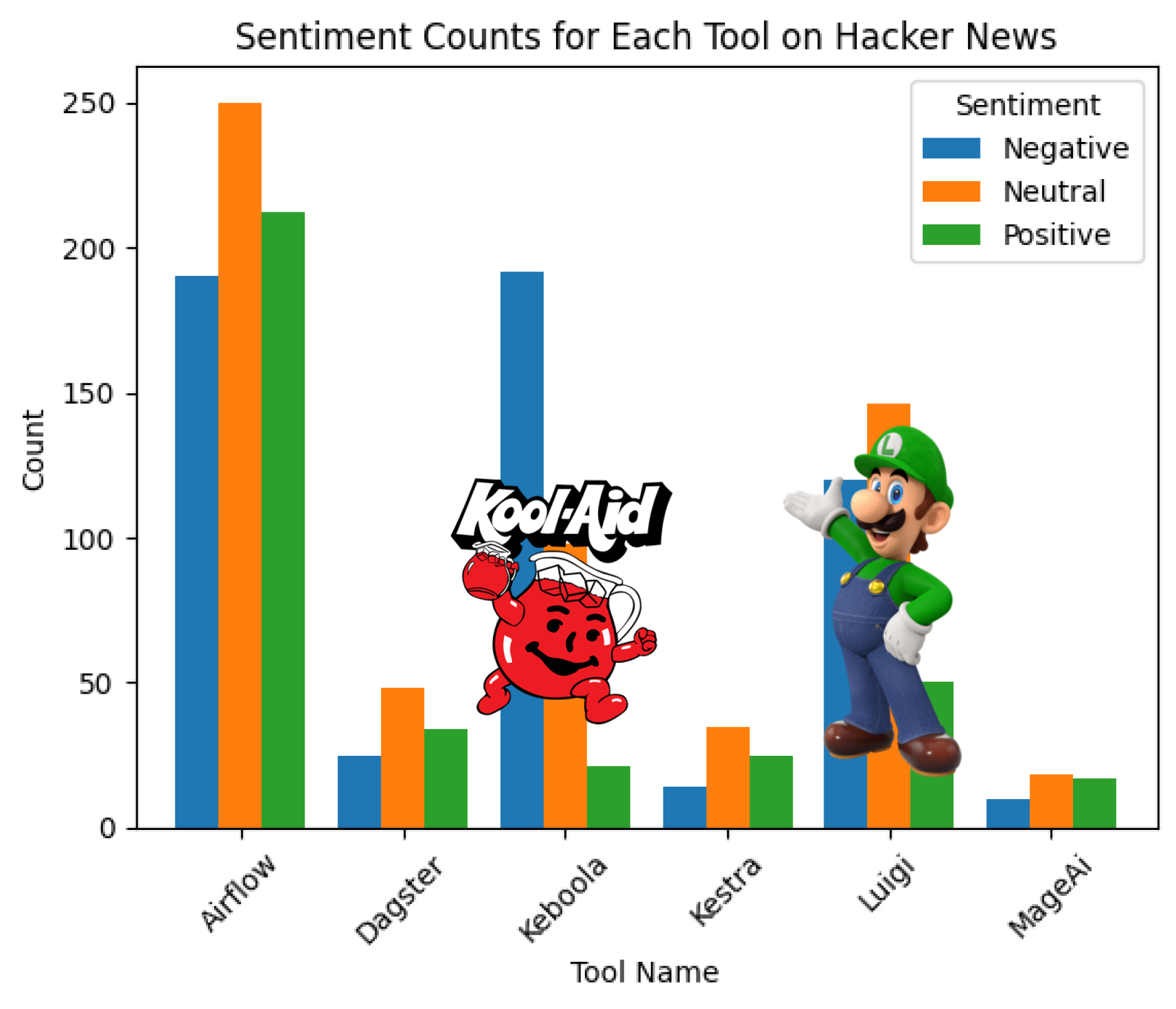
I understand if you're scratching your head at first glance, but let me clear things up. Remember those sneaky issues I mentioned with Keboola and Luigi earlier? Well, I've masked their charts with the respective “culprits”.
Now, onto the bars. Each trio of bars illustrates the count of negative, neutral, and positive comments on articles sourced from Hacker News that have at least one comment and were returned when searched for a specific orchestration tool, categorized accordingly by the specific data orchestration tool.
What's the big reveal? It seems like Hacker News readers tend to spread more positivity than negativity, though neutral comments hold their ground.
And, as is often the case with utilizing LLMs, this data should be taken with a grain of salt. It's more of a whimsical exploration than a rigorous analysis. However, if you take a peek behind Kool Aid and Luigi, it's intriguing to note that articles related to them seem to attract a disproportionate amount of negativity. 😂
… and you're just dipping your toes into the world of data orchestration, don’t sweat it. It's totally normal if it doesn't immediately click for you. For beginners, it can be tricky to grasp because in small projects, there isn't always that immediate need for things to happen "automatically" - you build your pipeline, run it once, and then bask in the satisfaction of your results - just like I did in my project. However, if you start playing around with one of these tools now, it could make it much easier to work with them later on. So, don't hesitate to dive in and experiment!
… And hey, if you're a seasoned pro about to drop some knowledge bombs, feel free to go for it - because what doesn’t challenge us, doesn’t change us 🥹. (*Cries in Gen Z*)
Yummy is a Lean-ops meal-kit company streamlines the entire food preparation process for customers in emerging markets by providing personalized recipes,
nutritional guidance, and even shopping services. Their innovative approach ensures a hassle-free, nutritionally optimized meal experience,
making daily cooking convenient and enjoyable.
Yummy is a food box business. At the intersection of gastronomy and logistics, this market is very competitive.
To make it in this market, Yummy needs to be fast and informed in their operations.
At Yummy, efficiency and timeliness are paramount. Initially, Martin, Yummy’s CTO, chose to purchase data pipelining tools for their operational and analytical
needs, aiming to maximize time efficiency. However, the real-world performance of these purchased solutions did not meet expectations, which
led to a reassessment of their approach.
What’s important: Velocity, Reliability, Speed, time. Money is secondary.
Martin was initially satisfied with the ease of setup provided by the SaaS services.
The tipping point came when an update to Yummy’s database introduced a new log table, leading to unexpectedly high fees due to the vendor’s default settings that automatically replicated new tables fully on every refresh. This situation highlighted the need for greater control over data management processes and prompted a shift towards more transparent and cost-effective solutions.
10x faster, 182x cheaper with dlt + async + modal
Motivated to find a solution that balanced cost with performance, Martin explored using dlt, a tool known for its simplicity in building data pipelines.
By combining dlt with asynchronous operations and using Modal for managed execution, the improvements were substantial:
Data processing speed increased tenfold.
Cost reduced by 182 times compared to the traditional SaaS tool.
The new system supports extracting data once and writing to multiple destinations without additional costs.
Taking back control with open source has never been easier
Taking control of your data stack is more accessible than ever with the broad array of open-source tools available. SQL copy pipelines, often seen as a basic utility in data management, do not generally differ significantly between platforms. They perform similar transformations and schema management, making them a commodity available at minimal cost.
SQL to SQL copy pipelines are widespread, yet many service providers charge exorbitant fees for these simple tasks. In contrast, these pipelines can often be set up and run at a fraction of the cost—sometimes just the price of a few coffees.
At dltHub, we advocate for leveraging straightforward, freely available resources to regain control over your data processes and budget effectively.
Setting up a SQL pipeline can take just a few minutes with the right tools. Explore these resources to enhance your data operations:
Statistical Data and Metadata eXchange (SDMX) is an international standard used extensively by global organizations, government agencies, and financial institutions to facilitate the efficient exchange, sharing, and processing of statistical data.
Utilizing SDMX enables seamless integration and access to a broad spectrum of statistical datasets covering economics, finance, population demographics, health, and education, among others.
These capabilities make it invaluable for creating robust, data-driven solutions that rely on accurate and comprehensive data sources.
SDMX not only standardizes data formats across disparate systems but also simplifies the access to data provided by institutions such as Eurostat, the ECB (European Central Bank), the IMF (International Monetary Fund), and many national statistics offices.
This standardization allows data engineers and scientists to focus more on analyzing data rather than spending time on data cleaning and preparation.
Eurostat (ESTAT) for the Purchasing Power Parity (PPP) and Price Level Indices providing insights into economic factors across different regions.
Eurostat's short-term statistics (sts_inpr_m) on industrial production, which is crucial for economic analysis.
European Central Bank (ECB) for exchange rates, essential for financial and trade-related analyses.
Loading the data with dlt, leveraging best practices
After retrieving data using the sdmx library, the next challenge is effectively integrating this data into databases.
The dlt library excels in this area by offering a robust solution for data loading that adheres to best practices in several key ways:
Automated schema management -> dlt infers types and evolves schema as needed. It automatically handles nested structures too. You can customise this behavior, or turn the schema into a data contract.
Declarative configuration -> You can easily switch between write dispositions (append/replace/merge) or destinations.
Scalability -> dlt is designed to handle large volumes of data efficiently, making it suitable for enterprise-level applications and high-volume data streams. This scalability ensures that as your data needs grow, your data processing pipeline can grow with them without requiring significant redesign or resource allocation.
Martin Salo, CTO at Yummy, a food logistics company, uses dlt to efficiently manage complex data flows from SDMX sources.
By leveraging dlt, Martin ensures that his data pipelines are not only easy to build, robust and error-resistant but also optimized for performance and scalability.
Martin Salo's implementation of the sdmx_source package effectively simplifies the retrieval of statistical data from diverse SDMX data sources using the Python sdmx library.
The design is user-friendly, allowing both simple and complex data queries, and integrates the results directly into pandas DataFrames for immediate analysis.
This implementation enhances data accessibility and prepares it for analytical applications, with built-in logging and error handling to improve reliability.
Integrating sdmx and dlt into your data pipelines significantly enhances data management practices, ensuring operations are robust,
scalable, and efficient. These tools provide essential capabilities for data professionals looking to seamlessly integrate
complex statistical data into their workflows, enabling more effective data-driven decision-making.
By engaging with the data engineering community and sharing strategies and insights on effective data integration,
data engineers can continue to refine their practices and achieve better outcomes in their projects.
Join the conversation and share your insights in our Slack community.
The versatility that enables "one way to rule them all"... requires a devtool
A unified approach to ETL processes centers around standardization without compromising flexibility.
To achieve this, we need to be enabled to build and run custom code, bu also have helpers to enable us to standardise and simplify our work.
In the data space, we have a few custom code options, some of which portable. But what is needed to achieve
universality and portability is more than just a code standard.
So what do we expect from such a tool?
It should be created for our developers
it should be easily pluggable into existing tools and workflows
it should perform across a variety of hardware and environments.
Data teams don't speak Object Oriented Programming (OOP)
Connectors are nice, but when don't exist or break, what do we do? We need to be able to build and maintain those connectors simply, as we work with the rest of our scripts.
The data person has a very mixed spectrum of activities and responsibilities, and programming is often a minor one. Thus, across a data team, while some members
can read or even speak OOP, the team will not be able to do so without sacrificing other capabilities.
This means that in order to be able to cater to a data team as a dev team, we need to aknowledge a different abstraction is needed.
Data teams often navigate complex systems and workflows that prioritize functional clarity over object-oriented
programming (OOP) principles. They require tools that simplify process definition, enabling quick, readable,
and maintainable data transformation and movement. Decorators serve this purpose well, providing a straightforward
way to extend functionality without the overhead of class hierarchies and inheritance.
Decorators in Python allow data teams to annotate functions with metadata and operational characteristics,
effectively wrapping additional behavior around core logic. This approach aligns with the procedural mindset
commonly found in data workflows, where the emphasis is on the transformation steps and data flow rather than the objects that encapsulate them.
By leveraging decorators, data engineers can focus on defining what each part of the ETL process does—extract,
transform, load—without delving into the complexities of OOP. This simplification makes the code more accessible
to professionals who may not be OOP experts but are deeply involved in the practicalities of data handling and analysis.
The ability to run embedded is more than just scalability
Most traditional ETL frameworks are architected with the assumption of relatively abundant computational resources.
This makes sense given the resource-intensive nature of ETL tasks when dealing with massive datasets.
However, this assumption often overlooks the potential for running these processes on smaller, more constrained infrastructures,
such as directly embedded within an orchestrator or on edge devices.
The perspective that ETL processes necessarily require large-scale infrastructure is ripe for challenge. In fact,
there is a compelling argument to be made for the efficiency and simplicity of executing ETL tasks, particularly web
requests for data integration, on smaller systems. This approach can offer significant cost savings and agility,
especially when dealing with less intensive data loads or when seeking to maintain a smaller digital footprint.
Small infrastructure ETL runs can be particularly efficient in situations where real-time data processing is not
required, or where data volumes are modest. By utilizing the orchestrator's inherent scheduling and management
capabilities, one can execute ETL jobs in a leaner, more cost-effective manner. This can be an excellent fit for
organizations that have variable data processing needs, where the infrastructure can scale down to match lower demands,
thereby avoiding the costs associated with maintaining larger, underutilized systems.
Running on small workers is easier than spinning up infra
Running ETL processes directly on an orchestrator can simplify architecture by reducing the number of
moving parts and dependencies. It allows data teams to quickly integrate new data sources and destinations with minimal
overhead. This methodology promotes a more agile and responsive data architecture, enabling businesses to adapt more swiftly
to changing data requirements.
It's important to recognize that this lean approach won't be suitable for all scenarios, particularly where data volumes
are large or where the complexity of transformations requires the robust computational capabilities of larger systems.
Nevertheless, for a significant subset of ETL tasks, particularly those involving straightforward data integrations via web requests,
running on smaller infrastructures presents an appealing alternative that is both cost-effective and simplifies the
overall data processing landscape.
Dealing with spiky loads is easier on highly parallel infras like serverless functions
Serverless functions are particularly adept at managing spiky data loads due to their highly parallel and elastic nature.
These platforms automatically scale up to handle bursts of data requests and scale down immediately after processing,
ensuring that resources are utilized only when necessary. This dynamic scaling not only improves resource efficiency
but also reduces costs, as billing is based on actual usage rather than reserved capacity.
The stateless design of serverless functions allows them to process multiple, independent tasks concurrently.
This capability is crucial for handling simultaneous data streams during peak times, facilitating rapid data processing
that aligns with sudden increases in load. Each function operates in isolation, mitigating the risk of one process impacting another,
which enhances overall system reliability and performance.
Moreover, serverless architectures eliminate the need for ongoing server management and capacity planning.
Data engineers can focus solely on the development of ETL logic without concerning themselves with underlying infrastructure issues.
This shift away from operational overhead to pure development accelerates deployment cycles and fosters innovation.
Dagster's embedded ETL now supports dlt - enabling devs to do what they love - build.
The "Stop Reinventing Orchestration: Embedded ELT in the Orchestrator" blog post by Pedram from Dagster Labs,
introduces the concept of Embedded ELT within an orchestration framework, highlighting the transition in data engineering from bulky,
complex systems towards more streamlined, embedded solutions that simplify data ingestion and management. This evolution is seen in
the move away from heavy tools like Airbyte or Meltano towards utilizing lightweight, performant libraries which integrate seamlessly into existing
orchestration platforms, reducing deployment complexity and operational overhead. This approach leverages the inherent capabilities of
orchestration systems to handle concerns typical to data ingestion, such as state management, error handling, and observability,
thereby enhancing efficiency and developer experience.
dlt was built for just such a scenario and we are happy to be adopted into it. Besides adding connectors, dlt adds a simple way to build custom pipelines.
The DAGWorks Substack post introduces a highly portable pipeline of all libraries, and leverages a blend of open-source Python libraries: dlt, Ibis, and Hamilton.
This integration exemplifies the trend towards modular, decentralized data systems, where each component specializes in a segment of the data handling process—dlt for extraction and loading,
Ibis for transformation, and Hamilton for orchestrating complex data flows. These technologies are not just tools but represent a
paradigm shift in data engineering, promoting agility, scalability, and cost-efficiency in deploying serverless microservices.
The post not only highlights the technical prowess of combining these libraries to solve practical problems like message
retention and thread summarization on Slack but also delves into the meta aspects of such integrations. It reflects on the broader
implications of adopting a lightweight stack that can operate within diverse infrastructures, from cloud environments to embedded systems,
underscoring the shift towards interoperability and backend agnosticism in data engineering practices. This approach illustrates a shift
in the data landscape, moving from monolithic systems to flexible, adaptive solutions that can meet specific organizational needs
without heavy dependencies or extensive infrastructure.
The concepts discussed here—portability, simplicity, and scalability—are central to modern data engineering practices. They reflect a shift towards
tools that not only perform well but also integrate seamlessly across different environments, from high-powered servers to minimal infrastructures like
edge devices. This shift emphasizes the importance of adaptability in tools used by data teams, catering to a broad spectrum of deployment scenarios without
sacrificing performance.
In this landscape, dlt exemplifies the type of tool that embodies these principles. It's not just about being another platform; it's about providing a
framework that supports the diverse needs of developers and engineers. dlt's design allows it to be embedded directly within various architectures,
enabling teams to implement robust data processes with minimal overhead. This approach reduces complexity and fosters an environment where innovation is
not hindered by the constraints of traditional data platforms.
We invite the community to engage with these concepts through dlt, contributing to its evolution and refinement. By participating in this collaborative
effort, you can help ensure that the tool remains at the forefront of data engineering technology, providing effective solutions that address the real-world
challenges of data management and integration.
Join the conversation and share your insights in our Slack community or contribute directly to the growing list of projects using us. Your expertise can drive
the continuous improvement of dlt, shaping it into a tool that not only meets current demands but also anticipates future needs in the data engineering field.
This demo works on codespaces. Codespaces is a development environment available for free to anyone with a Github account. You'll be asked to fork the demo repository and from there the README guides you with further steps.
Welcome to "Codex Central", your next-gen help center, driven by OpenAI's GPT-4 model. It's more than just a forum or a FAQ hub – it's a dynamic knowledge base where coders can find AI-assisted solutions to their pressing problems. With GPT-4's powerful comprehension and predictive abilities, Codex Central provides instantaneous issue resolution, insightful debugging, and personalized guidance. Get your code running smoothly with the unparalleled support at Codex Central - coding help reimagined with AI prowess.